
You launch a new Meta campaign, build a clean customer lookalike, and expect the old playbook to carry the account. Then results come back mixed. Reach looks broader than expected. Prospecting efficiency isn't as stable as it used to be. The audience you thought was tightly defined doesn't behave like a hard boundary at all.
That's where most advice on meta lookalike audiences falls short. It still teaches setup like it's 2019: pick a source, select 1%, duplicate a few ad sets, and wait for the algorithm to print conversions. That advice is incomplete now.
Lookalikes still matter. They can still be useful for acquisition, testing, and scale. But the job has changed. In the current privacy environment, success depends less on the audience feature itself and more on two things: the quality of the seed data you feed into Meta, and your ability to understand when Meta is honoring your input versus treating it as a suggestion.
What Are Meta Lookalike Audiences
Most advertisers start looking at lookalikes after they hit the same wall. Interest targeting gets noisy. Broad audiences feel unpredictable. Retargeting won't scale. You need a way to find net new people who resemble the customers already buying from you.
That's what Meta Lookalike Audiences were built to do. Meta rolled them out in 2013, and the feature works by taking a seed audience and finding similar users within a chosen country using a 1% to 10% similarity range. A 1% lookalike is the closest match to your source, while larger percentages increase reach but reduce similarity, as explained in this Meta lookalike audiences guide.
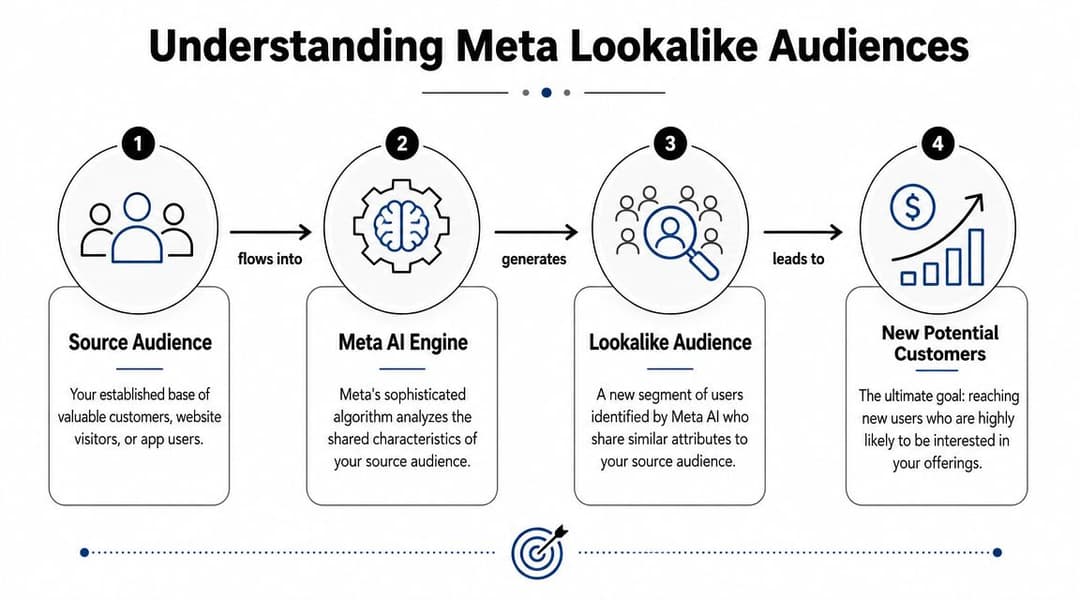
The simple way to think about them
A lookalike is a prospecting tool built from your own data. Instead of telling Meta, “Find people interested in fitness” or “Target skincare shoppers,” you give it a source audience such as buyers, qualified leads, app users, or engaged visitors. Meta then tries to find more users in that market who resemble them.
The key input is the source audience, sometimes called the seed. If that source is strong, the lookalike usually has a fighting chance. If the source is weak, the lookalike often just scales weak signals.
Practical rule: A lookalike doesn't create quality. It extends whatever quality already exists in the seed.
What the percentage actually controls
The percentage is where many teams make a bad assumption. It doesn't mean conversion probability. It controls how tightly Meta matches new people to the source audience.
Use the range as a trade-off:
- 1% lookalike gives you the closest modeled audience.
- Mid-range lookalikes widen the pool when you need more scale.
- Broader ranges up to 10% help with reach, but precision drops.
That's why practitioners often test multiple bands instead of betting on one version. Tight audiences can work well for direct response. Broader ones can help when creative is strong and the account needs room to spend.
Inside the Black Box How Meta Finds Similar Users
Meta doesn't build lookalikes by matching a few obvious traits. It models patterns. Think of it less like a demographic filter and more like a recommendation engine. The system looks at the people in your source audience and tries to identify overlapping signals that correlate with similar behavior.
That's why a lookalike built from purchasers can feel different from one built from casual visitors, even if both sources came from the same brand. Meta isn't just asking who these users are. It's asking how they behave.
What Meta is likely reading from the seed
You don't need to know every variable inside the system to use it well. You do need to understand the categories of signal that matter:
- On-platform behavior such as engagement with content, forms, or shopping experiences
- Site and app actions captured through tools like the pixel and app events
- Conversion feedback that tells Meta which users turned into customers
- Contextual patterns tied to device use, activity, and interaction history
If your event setup is messy, the model learns from messy inputs. If your conversion tracking is clean, the model has a better chance of finding higher-intent users.
For teams tightening event quality, it helps to review how the Meta Pixel works in practice before building audience strategies on top of it.
Why the algorithm can feel inconsistent
Marketers often blame lookalikes when performance drifts, but the audience is only part of the chain. The seed quality, the event quality, the optimization goal, the creative, and the account's learning history all shape outcomes.
A good way to think about it is music recommendations. If you train a system on your favorite niche albums, it will usually suggest more relevant tracks than if you train it on every song you've ever half-listened to. Lookalikes work the same way. Specific in, specific out.
Meta can only model what your source audience teaches it to value.
That's why “how Meta finds similar users” is really a question about signal clarity. The platform handles the computation. You control the examples.
Your Foundation for Success Choosing the Right Seed Audience
If there's one place where lookalike performance is won or lost, it's the seed. Not the campaign naming. Not the percentage slider. Not the latest audience hack. The source audience decides what Meta is trying to replicate.
That matters more now because the old browser-heavy signal stack isn't as dependable as it was. In the current environment, seed audience quality trumps size, and high-intent first-party data from CRM lists, offline conversions, and server-side tracking via the Conversions API has become more important after privacy changes reduced pixel reliability, as outlined in this analysis of Meta lookalike audience changes.
High-intent seeds usually beat broad seeds
A lot of accounts still build lookalikes from the easiest available source. All website visitors. All page engagers. Everyone who touched the funnel in any way. That gives Meta volume, but often not clarity.
A tighter seed from people who matter to the business tends to be more useful. Think purchasers, repeat buyers, qualified leads, subscribers, or validated offline conversions. These groups tell Meta what “valuable” looks like.
If you're mapping source choices to campaign goals, this breakdown of target audience types is a useful companion.
Seed Audience Source Comparison
| Seed Source | Signal Quality | Privacy Resilience | Best For |
|---|---|---|---|
| CRM customer list | High when segmented by buyer quality | Strong | Prospecting from known customer value |
| Offline conversions | High if data is accurate and timely | Strong | Businesses with sales happening off-site or in-store |
| Conversions API events | High when mapped cleanly to meaningful events | Strong | Accounts that need more durable server-side signals |
| Website visitors | Variable, often mixed intent | Moderate to weak | Broad top-of-funnel modeling when better data isn't available |
| Page or content engagers | Mixed | Moderate | Early testing, content-led brands, softer prospecting |
What works better in practice
The best seeds usually share three traits:
- They reflect buying intent. Purchasers and qualified leads beat generic traffic.
- They come from first-party systems. CRM and server-side sources hold up better when browser tracking drops signals.
- They're segmented with purpose. A seed made from all customers is often less useful than one built from repeat buyers or recent converters.
What tends not to work well is using convenience audiences just because they're easy to build. Big doesn't mean valuable. Broad visitor pools often contain curiosity clicks, accidental traffic, low-intent browsers, and people who will never buy.
The seed should represent the outcome you want more of, not just the traffic you happened to collect.
If the account has weak first-party data, fix that before obsessing over audience expansion, exclusions, or testing grids. Better source data usually produces more improvement than any downstream tweak.
A Practical Checklist for Creating Lookalike Audiences
A clean build in Ads Manager takes a minute. Getting a lookalike that helps performance depends on a few decisions that advertisers still get wrong, especially now that Meta expands aggressively and weaker seeds get exposed fast.
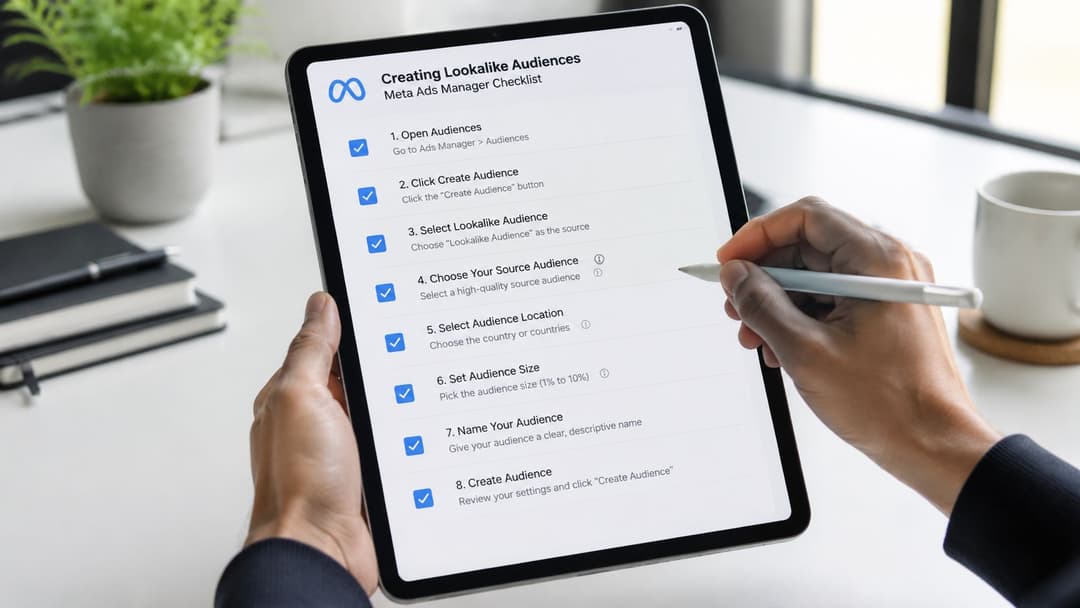
The setup sequence
Choose the source audience
Start with the cleanest, highest-intent seed available. Purchasers, qualified leads, repeat customers, app purchasers, and well-mapped server-side conversion events usually outperform broad traffic pools. Meta allows lookalikes from relatively small source audiences, but in practice, quality matters more than barely clearing the minimum threshold.Select the target country
Build lookalikes by market. Meta models similarity inside the country you choose, so a strong seed in one geography does not automatically transfer well to another.Pick the audience size
Audience percentage controls the trade-off between similarity and reach. Smaller percentages stay closer to the seed. Larger percentages give delivery more room, but the modeled audience gets looser.Name the audience clearly
Use a naming convention that includes source, geography, size, and recency. For example:Purchasers_180D_US_1%orSQL_CRM_UK_2%. Clear naming saves time once the account has multiple tests running.
How to choose the percentage
Start with the job the audience needs to do.
For efficient new-customer acquisition, tighter lookalikes usually make more sense. For broader prospecting or accounts trying to spend more without resetting the whole structure, wider ranges can be useful, especially if creative is strong and conversion signals are stable. If budget pressure is the bigger problem than audience quality, this guide on how to scale Meta ads profitably without wrecking efficiency is the more relevant next read.
A simple working approach:
- Use 1% to 2% for high-intent prospecting tests
- Test mid-range percentages if delivery is constrained or the market is small
- Use broader ranges carefully when spend needs room and the account has enough conversion volume to keep optimization on track
One practical caution matters more now than it did a few years ago. Creating a lookalike does not guarantee tight delivery against that exact modeled pool. With Advantage expansion and Meta's broader automation, the seed still matters, but the audience is often more of a directional input than a hard boundary. That is why weak source data creates problems quickly. The platform can optimize around a strong signal. It struggles when the seed itself is noisy.
This walkthrough is useful if you want to see the build flow visually.
From Prospecting to Scaling Key Lookalike Strategies
A common account pattern looks like this. The first 1% lookalike works, spend increases, frequency climbs, CPA starts drifting, and the team responds by stacking more audiences without changing the job each one is supposed to do. That usually creates overlap, muddier reporting, and very little real scale.
Lookalikes work better when each one has a specific role in the account. Prospecting, efficiency, and expansion should not all sit on the same audience logic.
For direct response campaigns, tighter lookalikes are still the right place to start. Broadly, smaller percentages tend to hold quality better than wider ones, which matches findings from a test where a 1% lookalike outperformed a 10% lookalike for lead generation. That does not mean 1% always wins. It means close-match modeling is usually the cleaner starting point when lead quality or first-purchase efficiency matters.
Use tight lookalikes for direct acquisition
Start with a narrow range built from a seed that reflects the outcome you want. Purchasers beat email subscribers. Qualified leads beat all leads. High-LTV customers beat mixed customer lists.
The trade-off is scale. Tight audiences often perform better early, but they can hit delivery limits faster, especially in smaller markets or accounts with aggressive budgets.
Use broader ranges when the account needs more spend capacity
Broader lookalikes help when spend is constrained and creative has room to keep working. They are often more useful as a scaling layer than as the first prospecting test.
That shift matters. A 5% to 10% audience gives Meta more room, but it also puts more pressure on the seed quality, conversion signal quality, and creative relevance. If those inputs are weak, broader modeling usually exposes the problem faster instead of fixing it.
For teams trying to increase spend without losing control of efficiency, this guide on how to scale Meta ads profitably without wrecking efficiency fits naturally alongside lookalike expansion decisions.
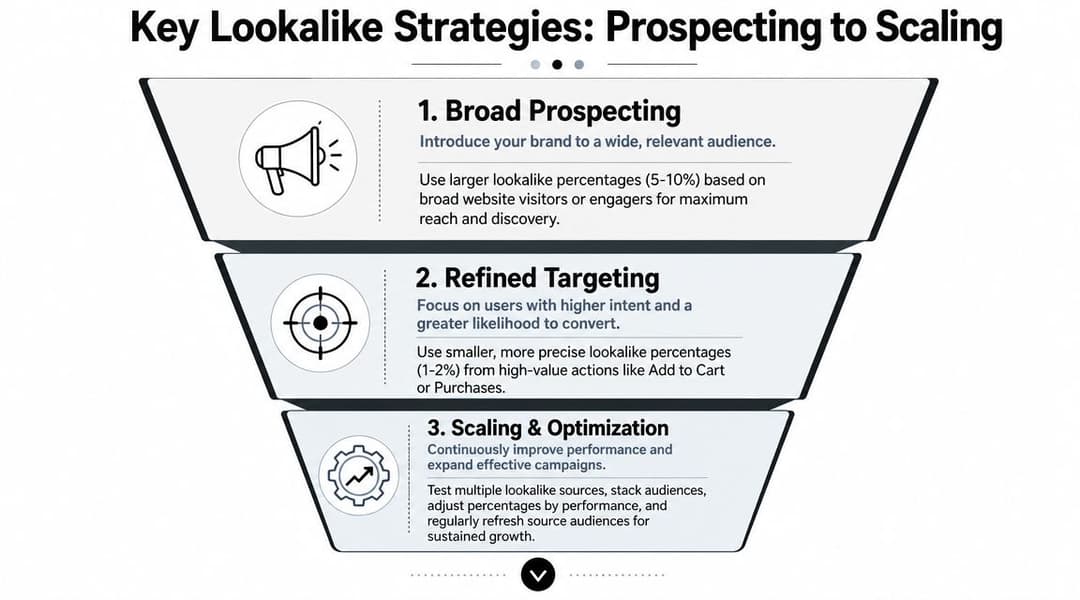
Three practical plays
Refined acquisition
Use 1% to 2% lookalikes from strong bottom-funnel seeds when the goal is efficient new customer acquisition or higher-quality leads.Scaling with controlled reach
Test broader bands only after the tighter version has proven it can convert. This keeps expansion tied to a winning signal instead of guessing with a wide audience from day one.Cross-sell and product-line expansion
Build a seed from buyers of a specific product or offer, then prospect for new users who resemble that segment. This works best when product lines attract meaningfully different customer profiles.
One rule keeps these strategies grounded. The audience percentage is not the strategy. The combination of seed quality, campaign objective, budget pressure, and creative strength is the strategy.
That is why some lookalike tests fail even when the setup looks correct in Ads Manager. The modeled audience may be fine. The seed may be too broad, too stale, or too weak to support the job you assigned to it.
Navigating Privacy Attribution and Automatic Expansion
The old assumption was simple: if you targeted a lookalike, Meta would stay inside it. That assumption doesn't hold reliably anymore.
For certain performance-focused objectives, marketers need to understand that lookalikes are often treated as targeting suggestions, not hard constraints. Meta may deliver beyond the defined lookalike audience if it predicts better results, a behavior described by Jon Loomer in his explanation of lookalike audiences and audience expansion.
Why this changes how you judge performance
If your campaign is optimizing for outcomes like sales, leads, or app promotion, the audience you selected may influence delivery without fully containing it. That means a lookalike ad set can perform well even when some of the performance comes from users outside the modeled group.
This doesn't make lookalikes useless. It changes what they are. In many setups, they function more like a signal source than a hard targeting wall.
Privacy loss made the seed even more important
At the same time, privacy changes reduced the reliability of browser-side tracking. So marketers lost certainty in two places at once: the quality of some signals dropped, and the rigidity of audience enforcement weakened.
That's why durable first-party infrastructure matters. If your event pipeline is thin, delayed, or noisy, Meta has less trustworthy data to model from and less trustworthy data to optimize against. Server-side event collection can help stabilize that foundation, which is why many teams have shifted toward the Meta Conversions API as part of audience and measurement strategy.
What to do differently now
Stop treating lookalikes as guaranteed walls around delivery. Use them as one input in a broader testing framework.
A practical operating model looks like this:
- Feed stronger seeds from CRM, offline, and server-side sources
- Watch incrementality and blended results, not just ad set labels
- Compare lookalikes against broad targeting, because broad can outperform in some accounts
- Reduce audience micromanagement when Meta's optimization is already expanding aggressively
The teams that adapt fastest are the ones that stop asking, “How do I lock Meta into this audience?” and start asking, “What signal am I giving the system, and is it strong enough to matter?”
Advanced Tactics for Lookalike Audience Optimization
Once the basics are in place, most gains come from better testing design. Not more random audience creation. Better sequencing, better source logic, and cleaner reporting.
One useful shift is moving from generic customer seeds to value-aware seeds. Instead of modeling all buyers the same way, build source audiences around the customers you want more of. Repeat buyers, recent purchasers, qualified subscribers, and offline-verified customers usually produce stronger learning signals than a blended customer file.
Test ranges like a system, not a guess
A solid workflow is to break lookalikes into tiers and evaluate them against the same offer, creative family, and optimization goal. That lets you learn whether the account responds better to tight precision, moderate expansion, or broader reach.
Common patterns include:
- Closest-match tier for acquisition efficiency
- Mid-band tier for balancing spend and quality
- Broader tier for prospecting scale and creative exploration
This is also where exclusions and overlap checks matter. If multiple lookalikes are active at once, you want a clear view of whether performance differences are real or just artifacts of delivery.
Automation helps when the matrix gets messy
Manual testing gets cumbersome fast. Every new source audience, percentage band, country, and creative angle multiplies the workload. Building those combinations in Ads Manager is manageable once. Running them consistently across brands, geos, or product lines is another story.
That's where platforms that operationalize testing can help. For example, AdStellar's Meta ads targeting best practices align with the kind of workflow performance teams need: structured audience variation, fast launch, and clearer readouts on which combinations are driving the business metric.
The more lookalike variations you test, the less this becomes an audience problem and the more it becomes an operations problem.
That's usually the inflection point. Not when a team needs more audience ideas, but when it needs a repeatable way to launch, compare, and refresh them without turning campaign management into spreadsheet maintenance.
Meta Lookalike Audiences FAQ
What's the minimum seed size?
Meta lets you build a lookalike from a relatively small source audience. The key question is whether that seed gives Meta enough useful signal to model from.
A seed built from weak inputs, such as all site visitors, often qualifies for creation but performs poorly. A smaller seed made up of recent purchasers, high-LTV customers, or qualified leads is usually a better starting point, even if scale is tighter.
Should you exclude the source audience?
Usually yes, especially in customer acquisition campaigns.
If the source is an existing customer list, excluding it keeps the campaign focused on finding new people instead of spending budget on users you already know. There are exceptions. Brands running retention, upsell, or win-back campaigns may want the opposite setup, so the right answer depends on the objective.
How often should you refresh lookalikes?
Refresh them when the source audience changes enough to reflect a different customer profile.
For high-volume accounts, that can mean regular updates because buyer behavior, product mix, and seasonality shift fast. For lower-volume advertisers, less frequent refreshes are fine. What matters is whether the seed still represents the customer you want more of.
Are lookalikes still worth testing against broad targeting?
Yes. They are still worth testing, but they should no longer be treated as the default winner.
In some accounts, broad targeting gives Meta more room to find conversions. In others, a strong lookalike built from clean first-party data still produces better efficiency or more stable scaling. The practical approach is to test both under similar creative, budget, and conversion conditions, then keep the audience type that earns its place.
Do lookalikes still work after privacy changes?
Yes, but the margin for error is smaller.
Privacy changes reduced match quality, delayed feedback, and made weak seed audiences less forgiving. That pushed lookalikes away from beginner setup tactics and closer to data quality work. Clean customer lists, server-side event coverage, and seed audiences tied to real business value matter more now than they did a few years ago.
Does Advantage expansion make lookalikes irrelevant?
No. It changes how much control you have.
Meta can expand beyond your selected audience when its systems predict better results, so a lookalike is often more of a starting signal than a hard boundary. That does not make lookalikes useless. It means performance depends even more on giving Meta a strong source audience and reading results at the business level, not assuming the audience definition alone caused the outcome.
If your team is building and testing lots of audience, creative, and campaign variations, AdStellar AI can help operationalize that workflow by automating bulk Meta campaign creation, audience variation testing, and performance analysis so you can spend more time interpreting signals and less time pushing setups manually.


